728x90
반응형
- 기본 퀵 정렬
- 퀵 정렬(quick sort)은 기준키를 기준으로 작거나 같은 값을 지닌 데이터는 앞으로, 큰 값을 지닌 데이터는 뒤로 가도록 하여 작은 값을 갖는 데이터와 큰 값을 갖는 데이터로 분리해가며 정렬하는 방법이다.

퀵정렬을 위한 데이터
- ① 맨 앞의 20을 기준키로 하고, 기준키 다음부터 기준키보다 큰 데이터를 찾아 50을 선택하고, 마지막 데이터부터 기준키보다 작은 데이터를 찾아 5를 선택한다. 그리고 선택된 50과 5를 교환한다.

- ② 계속해서 진행하여 기준키보다 큰 데이터인 40을 선택하고, 기준키보다 작은 데이터인 19를 선택한다. 그리고 두 수를 교환한다.

- ③ 마찬가지로 진행하여 기준키보다 큰 데이터인 40과 기준키보다 작은 데이터인 9를 선택한다. 그런데 발견된 위치가 서로 교차하는데, 이런 경우에는 두 값을 교환하지 않고 기준키 20과 작은 데이터인 9를 교환한다. 또한 기준키보다 큰 데이터를 발견하지 못하는 경우에도 기준키와 작은 데이터를 교환한다.

- ④ 데이터들을 보면 기준키 20을 기준으로 왼쪽에는 기준키보다 작은 데이터들이, 오른쪽에는 큰 데이터들이 있음을 알 수 있다. 이때 기준키를 중심으로 양분한다.

- ⑤ 기준키 9보다 큰 데이터인 18과 작은 데이터인 5를 선택하고 교환한다.

- ⑥ 마찬가지로 진행하여 큰 데이터인 18과 작은 데이터인 5를 선택하는데, 발견된 위치가 교차되므로 기준키 9와 작은 데이터인 5를 교환한다.
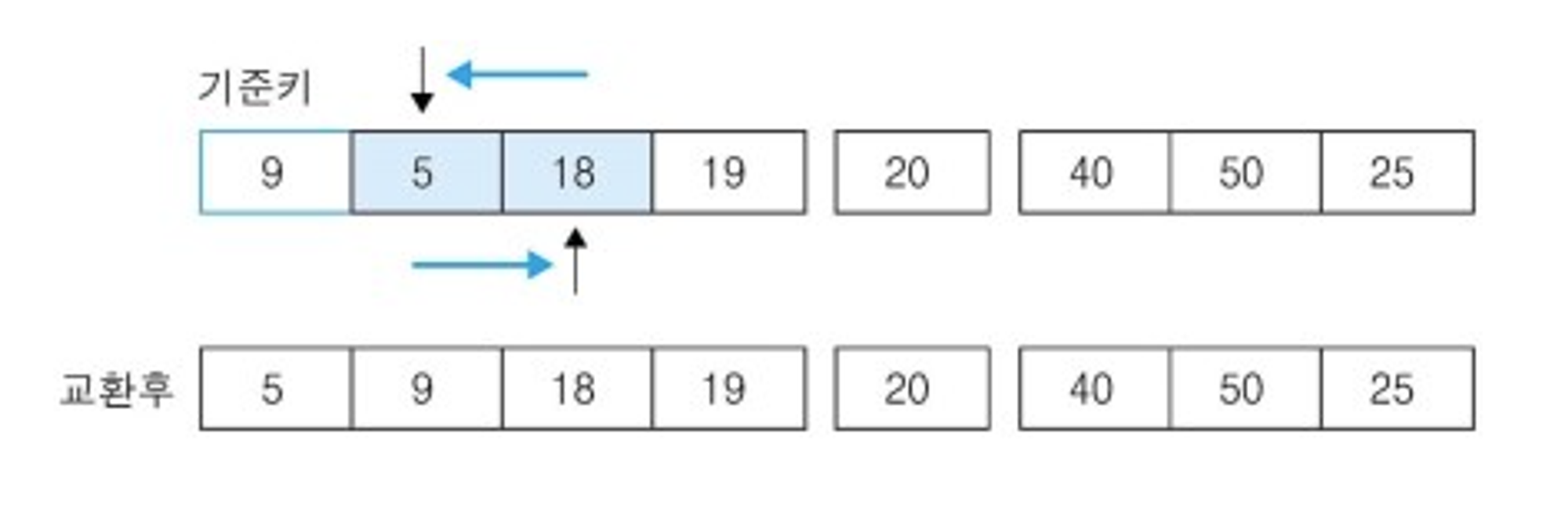
- ⑦ 그리고 기준키 9를 중심으로 양분한다.

- ⑧ {18, 19}에 대해 기준키 18보다 큰 데이터인 19와 기준키와 작거나 같은(같은 것도 포함됨) 데이터인 18을 선택하는데, 발견된 위치가 교차되므로 기준키 18과 기준키보다 작거나 같은 18을 교환한다.

- ⑨ 그리고 양분한다.

- ⑩ 이제 {40, 50, 25}에 대해 동작하게 되어 기준키 40보다 큰 50과 작은 25를 선택한다. 그리고 이 두 수를 교환한다.

- ⑪ 다음으로 큰 데이터인 50과 작은 데이터인 25를 선택하는데, 교차하므로 기준키 40과 작은 데이터인 25를 교환한다.

- ⑫ 그리고 기준키 40을 기준으로 양분한다. 모든 동작이 완료된다.

- 기본 퀵정렬 ver2
- 퀵정렬(Quick sort)은 불안정 정렬에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속합니다.
- 분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법입니다.
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략입니다.
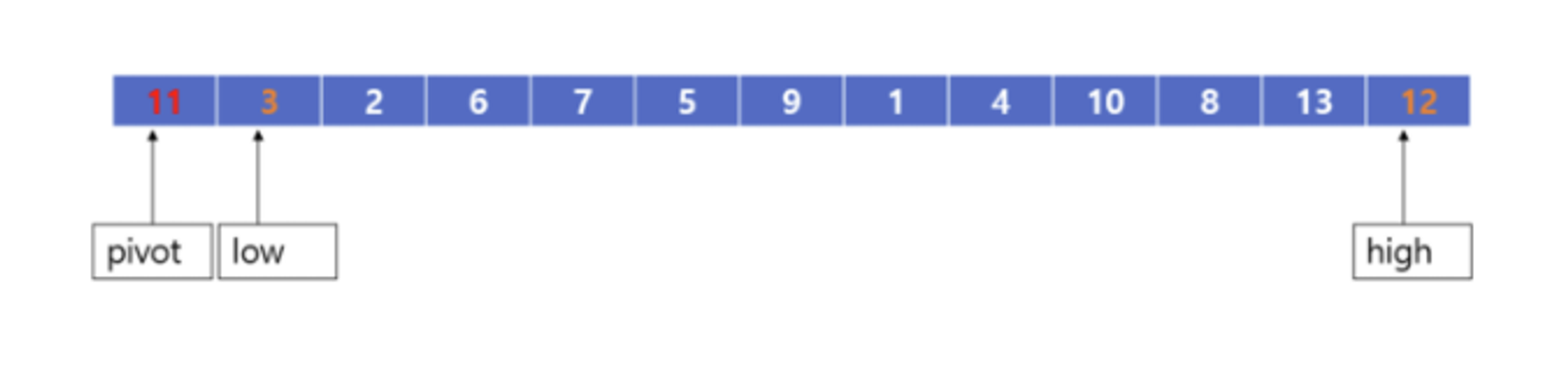
- 리스트에 값을 대입합니다. 리스트의 값은 다음과 같이 대입되어 있다고 가정합니다.

- 리스트에 기준이 될만한 값을 지정해줍니다. 저는 맨 왼쪽에 있는 11을 pivot으로 생각하겠습니다.

- pivot의 오른쪽의 인덱스를 low로 설정하고 리스트의 맨 마지막 인덱스를 high로 설정합니다.
- 위에서 정해준 pivot을 기준으로 pivot보다 작은 값들은 왼쪽으로 pivot보다 큰 값들은 오른쪽으로 옮겨줍니다. low은 pivot의 값과 비교했을 때 클 때까지 low의 값을 증가시켜주고, high는 pivot의 값과 비교했을 때 작을 때까지 비교해줍니다. 그러면 다음과 같이 low와 high가 나타나게 됩니다.

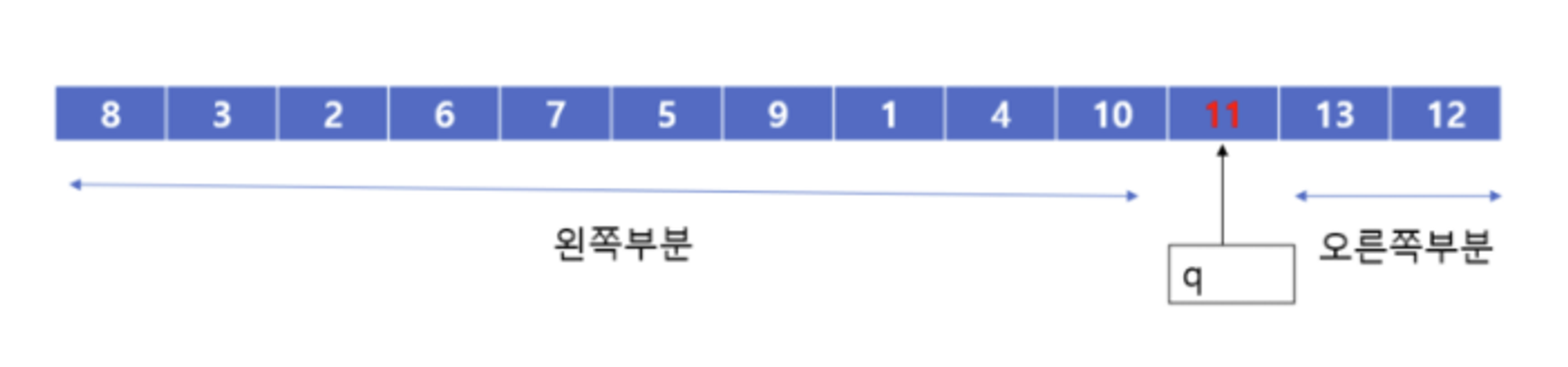
- 그리고 high의 값과 pivot의 값을 바꿔줘야 하므로 바꿔줍니다. 그러면 아래의 그림과 같이 나타나게 됩니다. 여기서 재귀적인 성질에 의해서 high를 기준으로 다시 재귀적으로 나뉘게 됩니다.
public class Quick {
public void sort(int[] data, int l, int r){
int left = l;
int right = r;
int pivot = data[(l+r)/2];
do{
while(data[left] < pivot) left++;
while(data[right] > pivot) right--;
if(left <= right){
int temp = data[left];
data[left] = data[right];
data[right] = temp;
left++;
right--;
}
}while (left <= right);
if(l < right) sort(data, l, right);
if(r > left) sort(data, left, r);
}
public static void main(String[] args) {
int data[] = {66, 10, 1, 34, 5, -10};
Quick quick = new Quick();
quick.sort(data, 0, data.length - 1);
for(int i=0; i<data.length; i++){
System.out.println("data["+i+"] : "+data[i]);
}
}
}
728x90
반응형
'Computer Science (CS)' 카테고리의 다른 글
| [Computer Science] 기수 정렬 (0) | 2023.11.26 |
|---|---|
| [Computer Science] 카운팅 정렬 (0) | 2023.11.26 |
| [Computer Science] 정렬(선택, 버블, 삽입) (0) | 2022.10.10 |
| [Computer Science] 힙(Heap) (0) | 2021.10.14 |
| [Computer Science] B-트리(B-Tree) (0) | 2021.10.14 |



